BOP-ASK: Object-Interaction Reasoning for Vision-Language Models
Abstract
Vision–Language Models (VLMs) have achieved impressive performance on spatial reasoning benchmarks, yet these evaluations mask critical weaknesses in understanding object interactions. Current benchmarks test high-level relationships ("left of," "behind", etc.) but ignore fine-grained spatial understanding needed for real-world applications: precise 3D localization, physical compatibility between objects, object affordances and multi-step spatial planning. In this work, we present BOP-ASK, a novel large-scale dataset for object-interaction reasoning for both training and benchmarking. Our data generation pipeline leverages 6D object poses from the Benchmark for Object Pose Estimation (BOP) datasets from which we derive fine-grained annotations such as grasp poses, referred object poses, path planning trajectories, relative spatial and depth relationships, and object-to-object relationships. BOP-ASK comprises over 150k images and 33M question–answer pairs spanning six tasks (four novel), providing a rich resource for training and evaluating VLMs. We evaluate proprietary and open-sourced VLMs, and conduct human evaluations on BOP-ASK-core, a contributed test benchmark. We also release BOP-ASK-lab, an out-of-distribution benchmark with images not sourced from BOP, enabling testing of generalization. Our experiments demonstrate that models trained on BOP-ASK outperform baselines and exhibit emergent capabilities such as precise object and grasp pose estimation, trajectory planning, and fine-grained object-centric spatial reasoning in cluttered environments. We will publicly release our datasets and dataset generation pipeline.
Key Findings
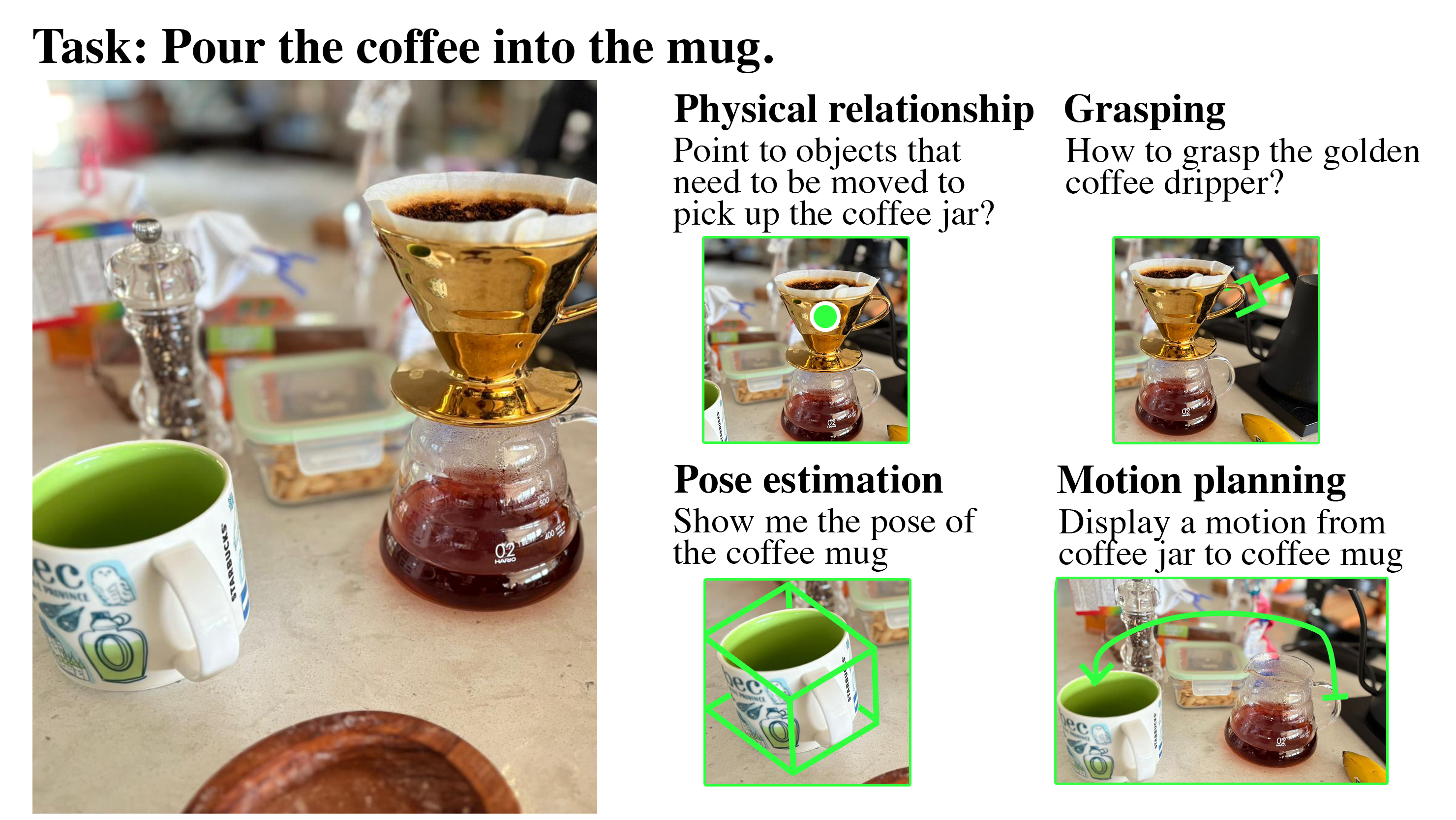
Reliable robot manipulation requires more than detecting objects—it requires understanding how objects interact in space. BOP-ASK directly addresses this need by offering detailed supervision for physical relationships, grasping cues, precise poses, and object-to-object motion planning, enabling models to learn manipulation skills that match human spatial intuition.
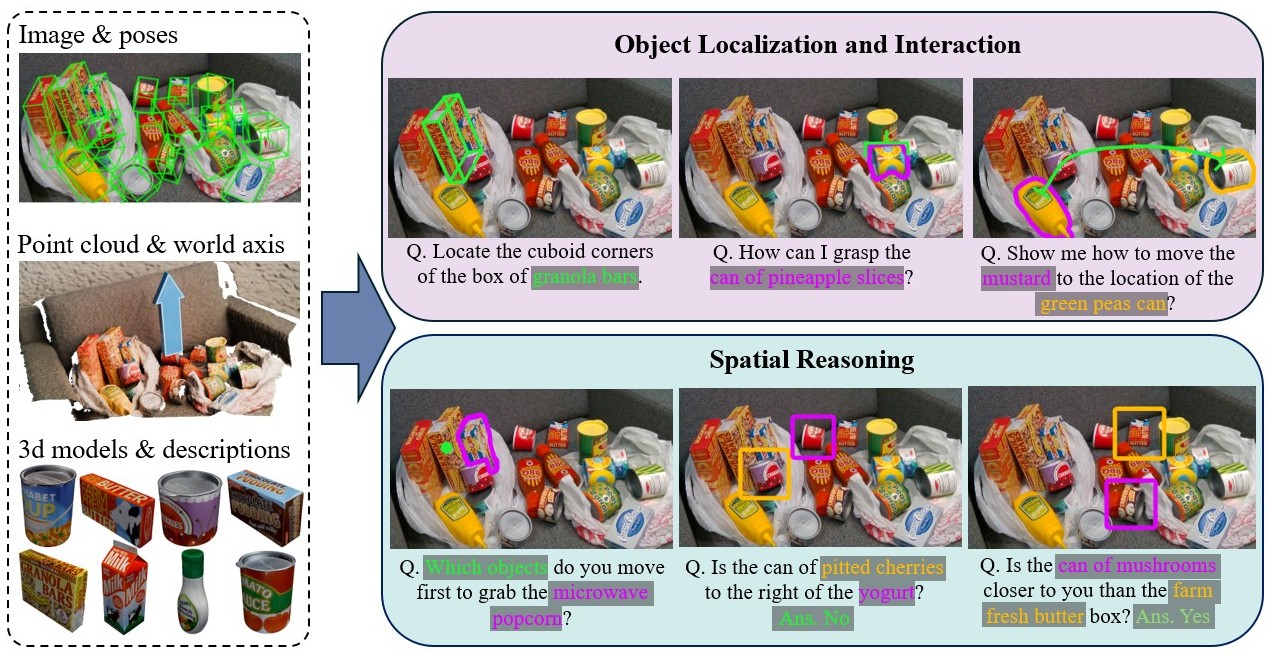
We automatically derive object-interaction and spatial reasoning annotations from 3D point clouds, images, object poses, and 3D models. BOP-ASK includes question–answer pairs spanning six tasks: pose estimation, grasp affordance, motion planning, physical interaction, object relationships, and depth relationships.
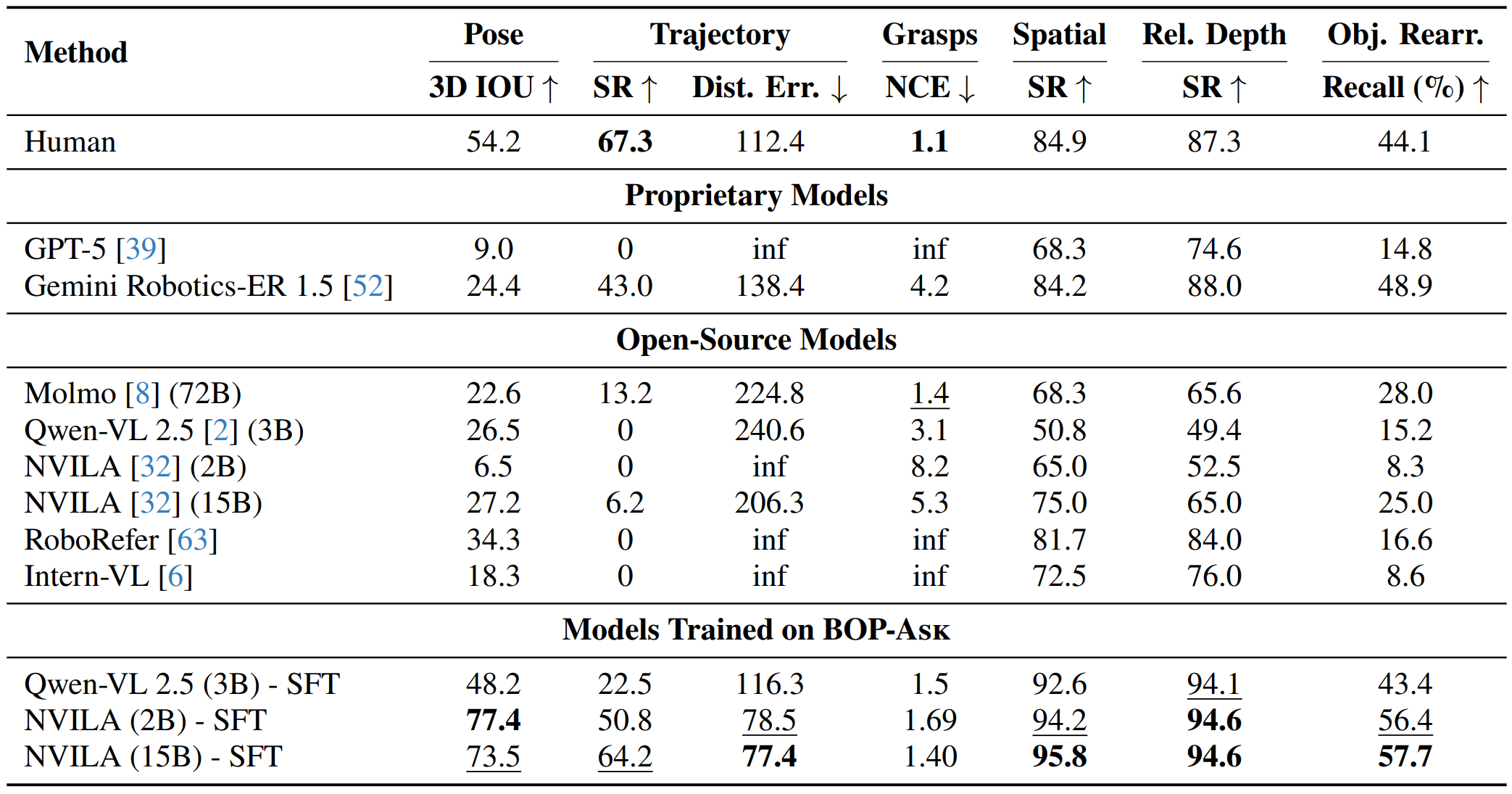
We evaluate a wide range of proprietary and open-source VLMs on BOP-ASK and observe substantial shortcomings in object-interaction reasoning. Models trained on BOP-ASK (last three rows) exhibit strong skill transfer and robust reasoning in unseen scenes.

Real world robot experiments with a Franka arm and a ZED2 Stereo camera. VLMs fine-tuned on BOP-ASK can perform tasks such as visual grounding (step 1), grasping (step 2,4) and motion planning (step 3,6).
Dataset Details

Predictions from BOP-ASK test sets. NVILA predictions (magenta) and NVILA SFT (fine-tuned on BOP-ASK) predictions (blue) are shown alongside Ground Truth (green). For the Rearrangement task, the Ground Truth shape marks the valid prediction region. Missing color indicates no prediction or an out-of-frame result. Images from HOPE, HANDAL, and YCB-V.
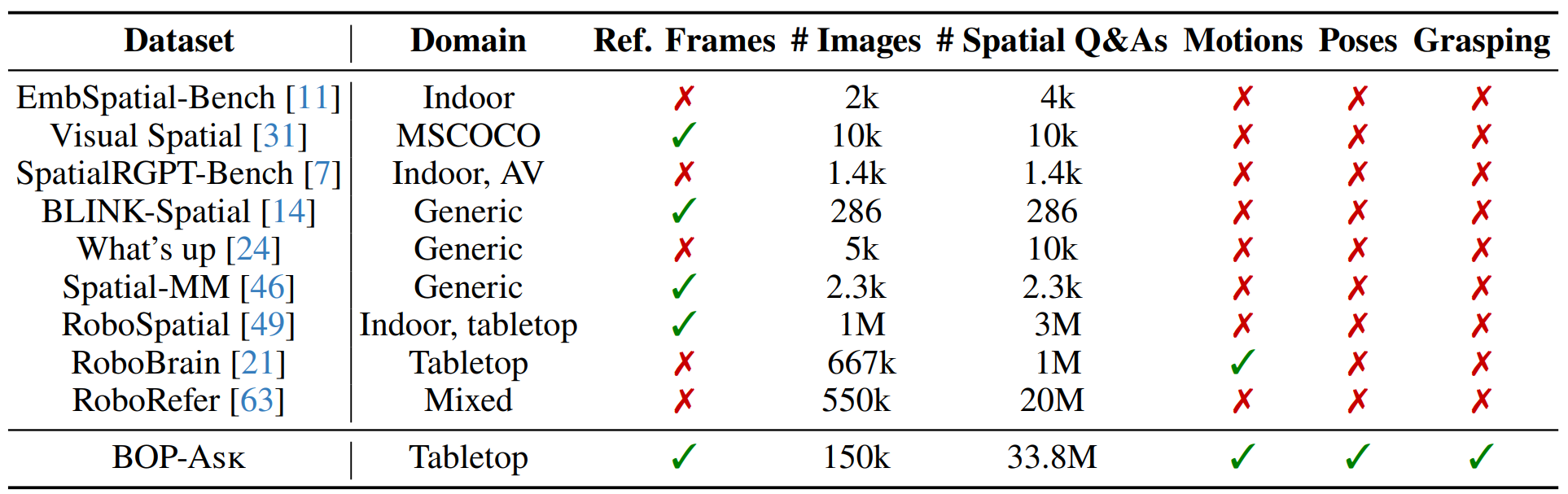
Comparison with spatial reasoning datasets including reference frames and whether they provide motions, poses, and grasping. Only BOP-ASK includes all three.

Distribution of questions and frequency in BOP-ASK.
BibTeX
@article{bhat2025bop,
title={BOP-ASK: Object-Interaction Reasoning for Vision-Language Models},
author={Bhat, Vineet and Kim, Sungsu and Blukis, Valts and Heinrich, Greg and Krishnamurthy, Prashanth and Karri, Ramesh and Birchfield, Stan and Khorrami, Farshad and Tremblay, Jonathan},
journal={arXiv preprint arXiv:2511.16857},
year={2025}
}